
I started aiming at data science in 2010. My degree was in information systems, which in practice meant a hybrid of business and computer science that still left a lot of the real work up to you. If you wanted to do serious text work, nobody was going to hand you a perfect lab. You had to find text, collect it, clean it, and then decide whether your methods actually held up once language got messy.
For me, the original Twitter API was one of the first places where that became possible at the right scale. It gave me live public language, fast enough to experiment with and messy enough to be useful.
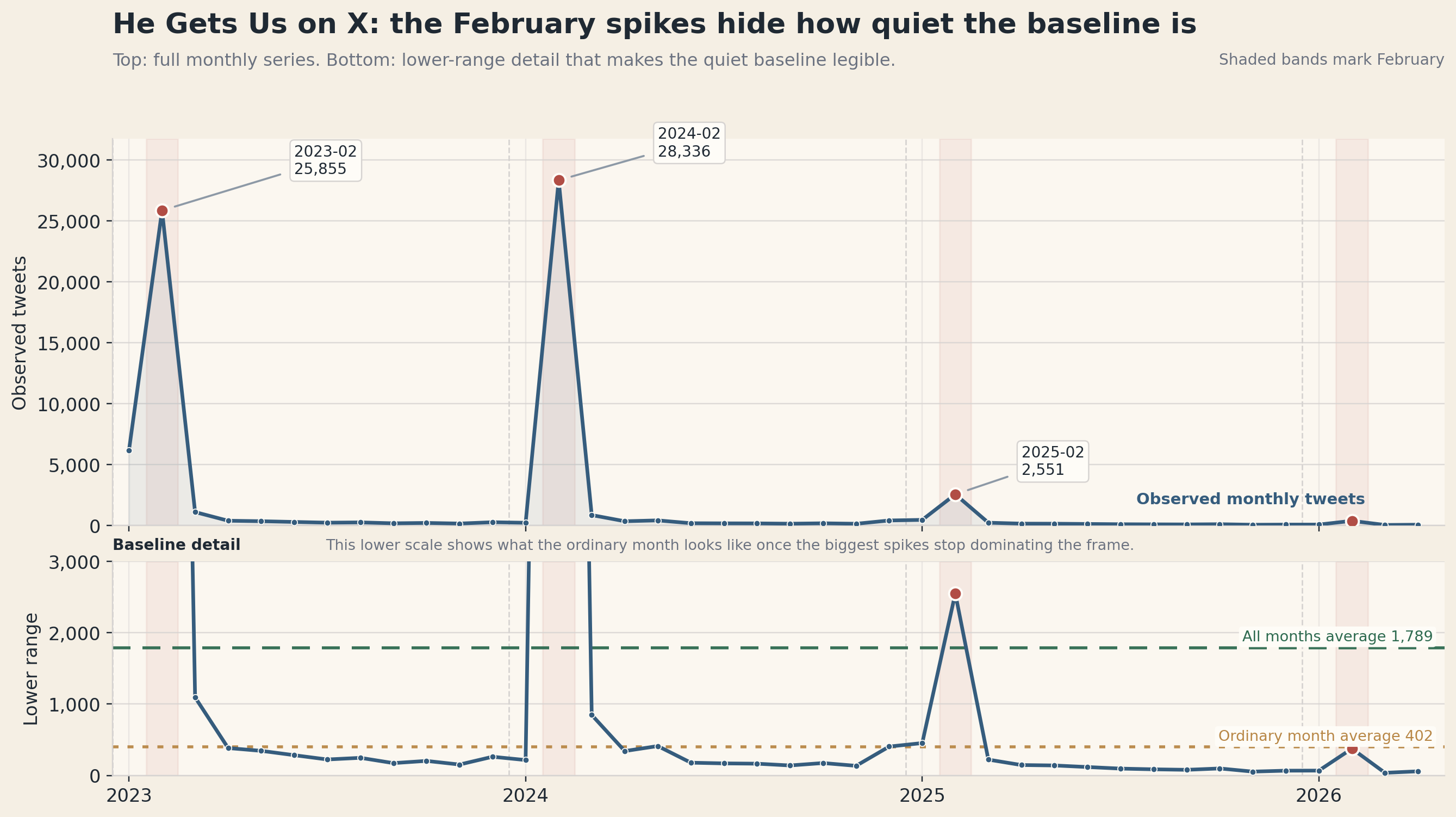
1,789 posts in the full average month, but closer to 402 once February is set aside.
The Work Was Self-Taught By Necessity
The early version of this work was simple in the best way.
- pull a block of public text
- test tokenization and n-grams
- see which words kept clustering together
- try to separate what was real signal from what was just repeated noise
Later, as the open-source tooling got better, I kept layering on more.
- token and phrase work
- word-vector style exploration
- entity extraction
- more formal text cleaning
A lot of that work happened at night before I ever tried to move it into day-job applications, which gave me room to fail privately, learn the mechanics, and only bring the methods forward once they were stable enough to trust.
Why Twitter Mattered Then
Twitter was useful because it sat in the middle of three things I cared about.
First, it was public. You could see how people actually talked when there was no interviewer in the room.
Second, it was timely. If something happened, the language changed immediately.
Third, it was dense. One day of posts could give you enough text to see patterns, test filters, and ask whether a topic had structure or was just random chatter.
That made it one of the best practice grounds for anyone trying to learn applied text analytics before “AI” became the label everyone used for everything.
Why I Came Back To It
When Twitter became X, a lot changed around the API:
- the branding changed
- the pricing changed
- the product language changed
- the public conversation about whether it was still worth using changed
What I wanted to know was more practical: could I still use it as a real research substrate, a working public-text system where the acquisition logic, the cost, and the resulting analysis all had to stand up together?
That is why I funded the API again. I wanted to know the difference between what the Twitter API had been historically and what the X API actually is now when you are the one paying for the requests.
The answer has gotten clearer as the same pattern moved into later institutional, survey, and stakeholder lanes. The current method is deliberately slower: test the visible surface, count first, buy the smallest useful post-only block, inspect the stored evidence, and then decide whether the next dollar should buy more posts, account context, a quote/reply follow-on, or nothing at all.
Why He Gets Us Was The Right Test Case
He Gets Us was the right public dataset for that test because it was not a topic I was meeting cold.
McQueen Analytics has done more than 150,000 surveys touching the campaign over time. At points that was roughly 800 a week for a couple of years. So I already knew something important going in:
- the campaign had real public salience
- it had clear tent-pole moments
- it created strong reactions
- and X had always felt like the missing public-text layer around that work
I had used TweetDeck-style monitoring anecdotally for years. I would keep it open, watch specific reactions, and bring individual posts into analysis when they felt important. But that is not the same thing as having a governed corpus you can actually measure.
That gap is what this series is really about.
Later work made that gap sharper. A large institutional topic, a survey-support topic, and a low-volume stakeholder topic do not ask the API for the same thing. One may need historical windows. One may need objection language. One may need only counts to prove the public surface is too thin. The method has to notice the difference before the money is spent.
The Real Question
I wanted to know what happened when I took a campaign I already knew well, paired it with the current X API, and built a public-text workflow disciplined enough to trust.
That led to the rest of the story:
- what the X API is now
- how to think about its cost model
- how I rebuilt the collection method around counts, small post-only pulls, stored snapshots, and stop rules after wasting money on the first pass
- and what the He Gets Us dataset actually says once you move past anecdotes
I have a couple of post series prepared that will roll out on Tuesdays and Thursdays over the next few weeks.