He Gets Us was the obvious choice on fit. I already knew the campaign from the survey side, and a careful X pull should show me something the survey file could not.
Why this topic was worth paying for
McQueen Analytics had done a large amount of He Gets Us work over time. What I did not have was a governed X corpus I could read at scale.
I wanted four things:
- pull the campaign conversation from 2023 forward
- keep the query tight enough that generic “he gets us†language would not swamp the corpus
- exclude the soccer and football false positives that show up when a phrase is broad
- preserve the timing structure around the campaign's big tent-pole moments
The final query reflects those limits. It requires a campaign anchor such as HeGetsUs, hegetsus.com, @HeGetsUs, or the exact spaced phrase paired with campaign language like ad, commercial, Super Bowl, Come Near, or controversial.
The first pull did not start there.
The naive first pass
My first larger pass was too broad and too expensive.
I did what a lot of researchers do when a platform opens back up:
- I pulled the broad historical space
- I let user expansion do more work than the question required
- and I learned the cost lesson after the fact
In plain language, I watched a few research dollars flap away toward X before I tightened the pull.

The mistake was useful only because it forced the next version of the method into the open.
What changed after that
I stopped treating the job as one big corpus hunt. I split it into acquisition decisions.
Job 1: Size the universe
Counts answered the first question: the current family view shows 74,448 observed posts across the latest stored counts runs. That told me how big the conversation was before I paid to pull more text.
Job 2: Recover the historical text cheaply
For the older 2023-2024 story, the lower-cost post-only archive lane was enough. That lane now carries 44,519 stored posts from 2023-01-01 through 2024-05-31 UTC, and it became the backbone of the timing and text read.
Job 3: Keep the broader monitoring view
The broader monitoring lane stayed in place for the current view, with owned-link amplification kept as a separate sibling where it helped.
The family view now has:
50,812unique stored posts57,951stored family rows29,607authors- date range from
2023-01-01through2026-04-21UTC
I can call that roughly 50,000 posts in public language, but the exact counts still stay visible.
Why the family splits into lanes
One of the clearest lessons from this project is that one topic does not always equal one acquisition lane.
The governed He Gets Us family now combines:
- broad campaign monitoring
- a cheaper post-only historical recovery lane
- an owned-link amplification lane
This can sound like back-office bookkeeping. It changes the analysis.
It lets me keep these questions separate:
- how much public language exists around the campaign?
- how much of that is direct authored discourse?
- how much is link-sharing or preview-driven amplification?
- when does richer user expansion earn its cost?
That last question is more consequential than people think, because user hydration is often where the cost starts climbing fast.
What the query hygiene says
The stored family covers a wide surface, and the query rules still keep it disciplined.
In the unique-post read:
45,563posts contain visible campaign anchors in the text itself2,944are URL-only or preview-driven matches2,305are residual rows with no obvious visible anchor
The split is healthy. Most of the corpus is real direct discourse rather than passive link traffic.
I do not need to pretend every row is the same kind of evidence.
That distinction carries through into public writing. A person saying something directly about the campaign is not the same as someone boosting a preview card.
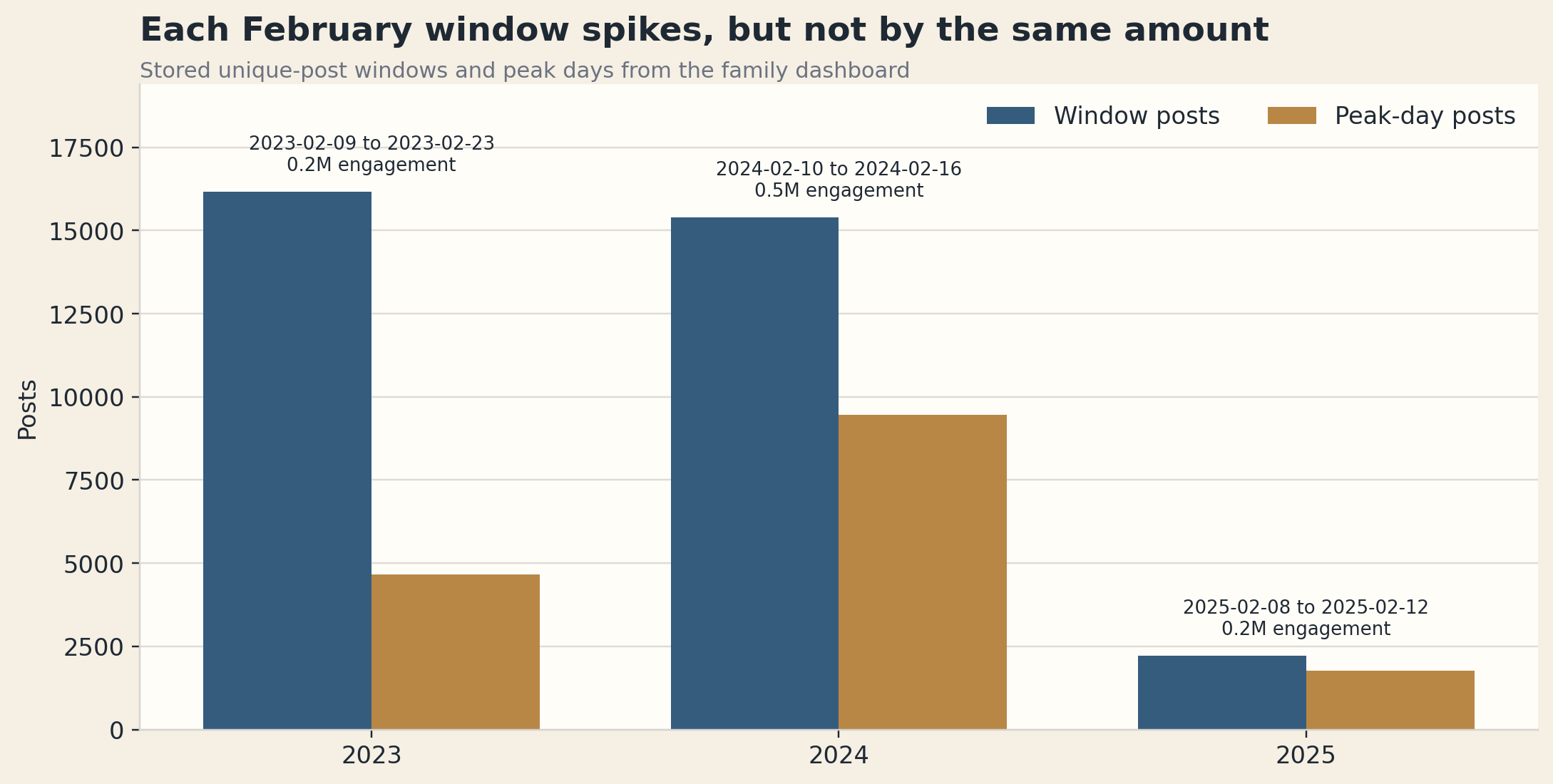
What the timing surface proved
The dataset is not evenly distributed across the whole period. It clusters hard around campaign interruptions.
The three biggest grouped windows are:
2023-02-09through2023-02-232024-02-10through2024-02-162025-02-08through2025-02-12
Counts-first collection showed that pattern early. I could see the dense days, the expensive days, and the cheap recovery opportunities before buying the next block of text.
The method got better because the spending became tied to a question.
What I would do again
The first version of this work taught me something simple:
the X API will absolutely let you learn by overspending if you let it.
The better version of the workflow looks like this:
- count first
- buy the densest missing windows first
- default to post-only historical recovery when the question is really about language and timing
- save richer user expansion for the questions that require it
The costly pull became a reusable research lane once the gate was clear.
And once the corpus was shaped correctly, the findings got much more interesting than the collection story.