
2023 and 2024, returns as a smaller echo in 2025, and stays muted in 2026.
The simplest honest surface read is straightforward: on X, He Gets Us behaves less like a calm always-on brand channel and more like a recurring event-triggered argument surface.
You can see that before any deeper modeling starts. The timing, the repeated language, and the February surges are all visible in the first pass.
The timeline is the first finding
The monthly pattern does most of the explanatory work on its own.

402 observed tweets. February reaches roughly 64x that baseline in 2023, 71x in 2024, then falls back toward the ordinary range by 2026.
That count pattern is not subtle. 2023-02 reaches 25,855 observed tweets, 2024-02 climbs to 28,336, and even the smaller 2025-02 wave still lands at 2,551 once the surrounding months have dropped back down.
That also clarifies the 2025 question. In the family overview, 2025-02 shows 2,460 stored posts against 2,551 observed tweets, so the smaller wave looks like a real drop from the earlier February peaks rather than a missing-month artifact.
For readers, the key point is simple: this topic is overwhelmingly February-shaped.
That repetition tells you immediately that the campaign's X life is driven by tent-pole interruption, especially the Super Bowl, more than by steady background conversation.
The windows make the pattern clearer
The grouped activity windows sharpen the same point.
2023-02-09to2023-02-23:16,172stored posts, peak day2023-02-13with4,6552024-02-10to2024-02-16:15,395stored posts, peak day2024-02-12with9,4622025-02-08to2025-02-12:2,228stored posts, peak day2025-02-10with1,768
The scale changes year to year, but the structure stays recognizable.
The campaign shows up as a wave, not as a flat line.
The surface vocabulary stays stable
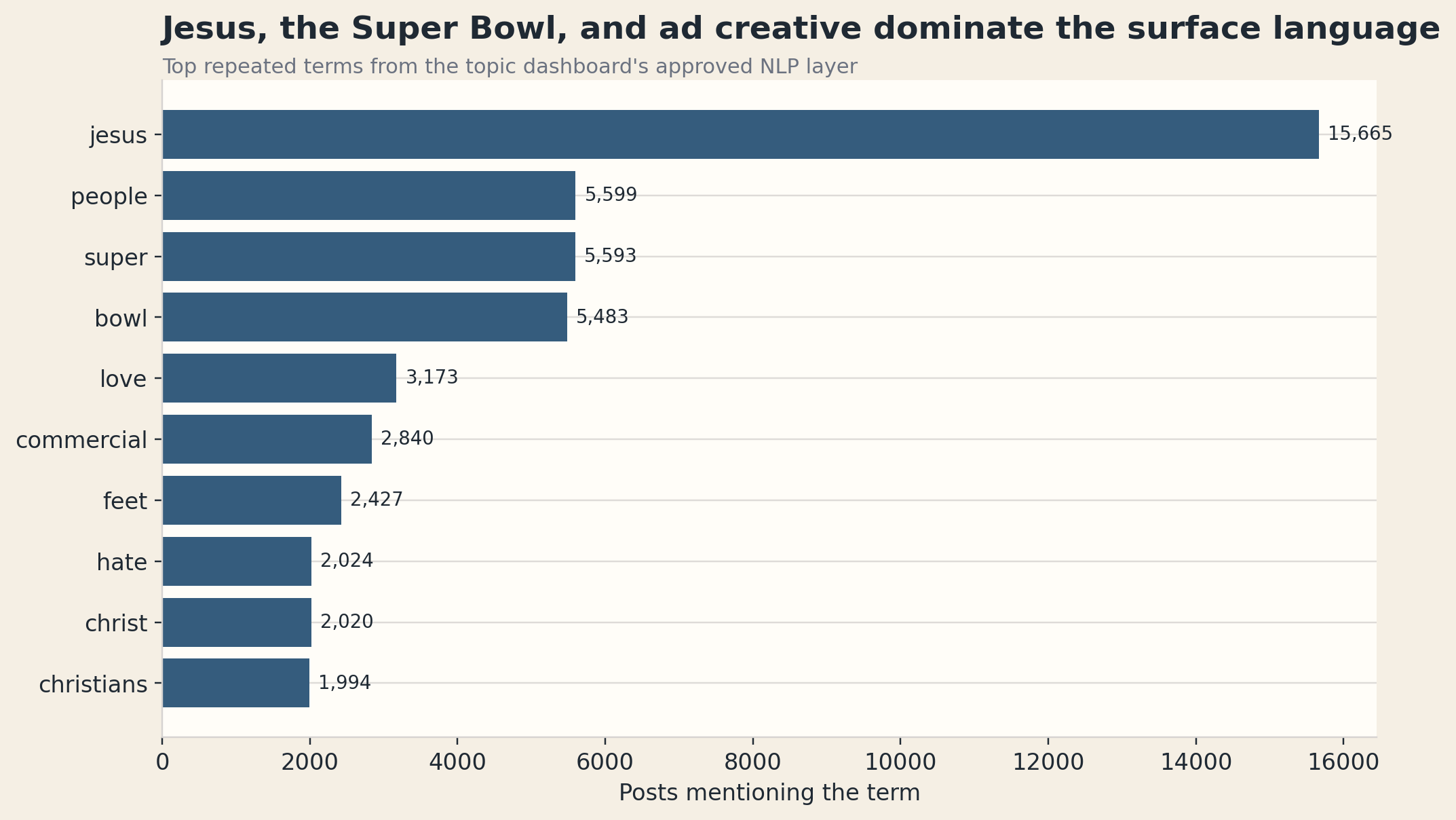
The most common words in the corpus are not mysterious:
jesuspeoplesuperbowllovecommercialfeethatechristchristians
That term mix shows the conversation does not stay at the level of ad performance. It keeps collapsing back into a small set of durable public meanings:
- Jesus
- ad creative
- the Super Bowl
- moral or theological judgment
In other words, the surface language does not stay neutral for long.
February changes the terms people reach for
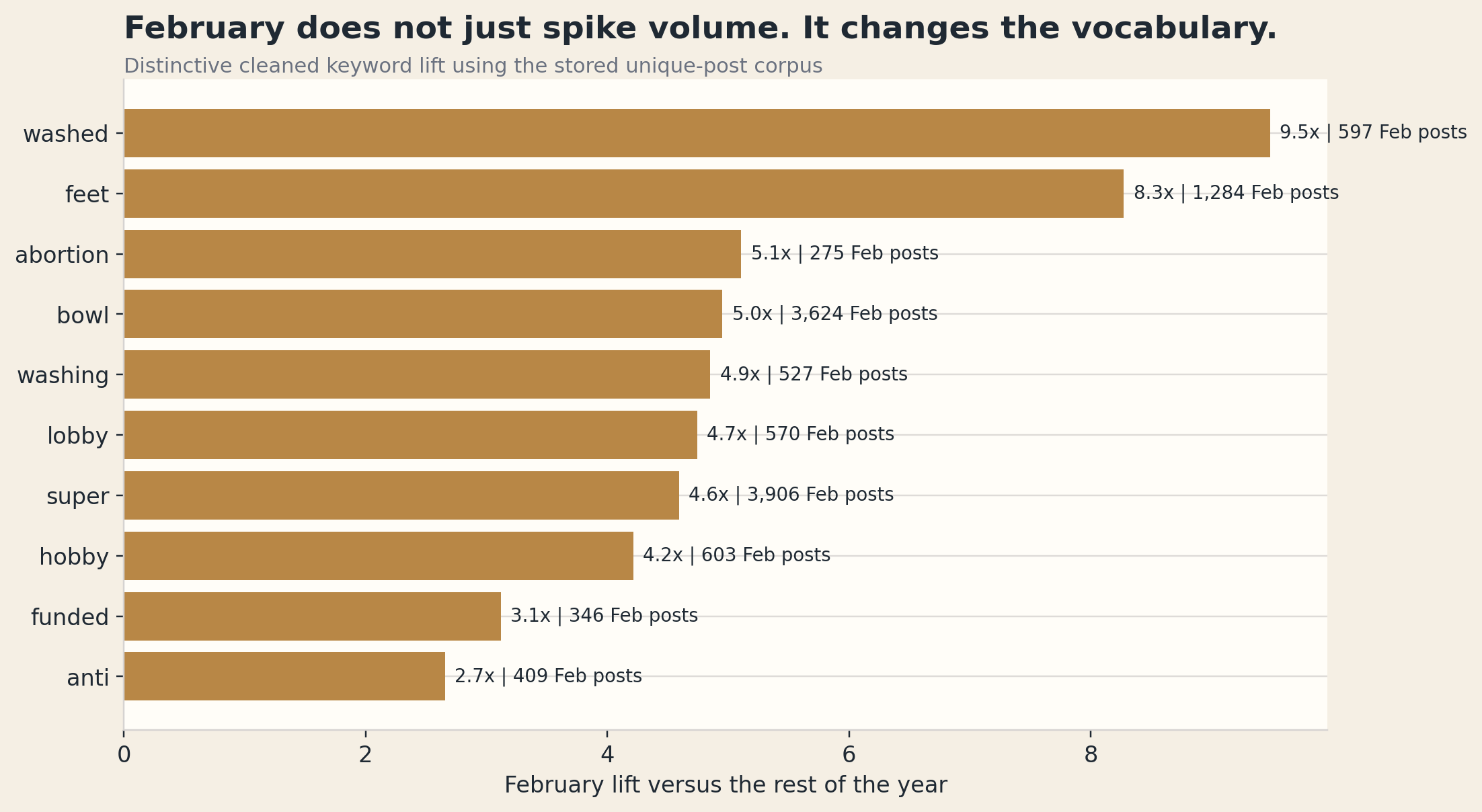
When I compared February to the rest of the year, the distinctive language was exactly what you would expect from the campaign's biggest flashpoints:
washedfeetwashingabortionsuperbowlhobbylobbyfunded
The distinctive terms compress the whole topic.
In February, the campaign is read less as background brand language and more as a fight over:
- the creative itself
- the theology implied by the creative
- the funders behind it
- and whether the whole project is soft compassion, soft politics, or soft rebranding
What it looks like from the outside
From the outside, just taking in the public tweets, this looks like:
- The campaign did break through on X.
- That attention clustered around major event windows, especially February and the Super Bowl.
- The language around it was not mostly “brand love.â€ÂÂÂÂÂÂÂ
- It was a mix of curiosity, critique, theology, and reactions to the ad creative itself.
That is enough to make the dataset worth studying before any heavier modeling starts.
A few clean examples
The highest-signal public examples on the surface tend to fall into three buckets.
Provenance critique
The campaign gets pulled into arguments about who funds it, what else those funders support, and whether the campaign's public tone hides a harder underlying politics.
Theology critique
The campaign gets judged on whether it presents Jesus in a way that is faithful, watered down, or strategically vague.
Skeptical inquiry
A meaningful slice of people are skeptical and investigative rather than simply angry. They are trying to understand what the campaign is, why it is spending this much money, and what the actual agenda is.
The surface read matters because it shows several distinct lanes before the deeper pass starts.
What this can and cannot tell us
X cannot be the only source for understanding the campaign.
That is especially true here because X was not one of the campaign's main owned-presence channels in this dataset. It was mostly a place where people responded to the campaign from the outside.
So the useful finding is narrower:
the campaign repeatedly created moments that people argued about in public.
The next question is what kind of argument, who carried it, and whether the loudest slices of the conversation were also the most important.
The next part starts there.