
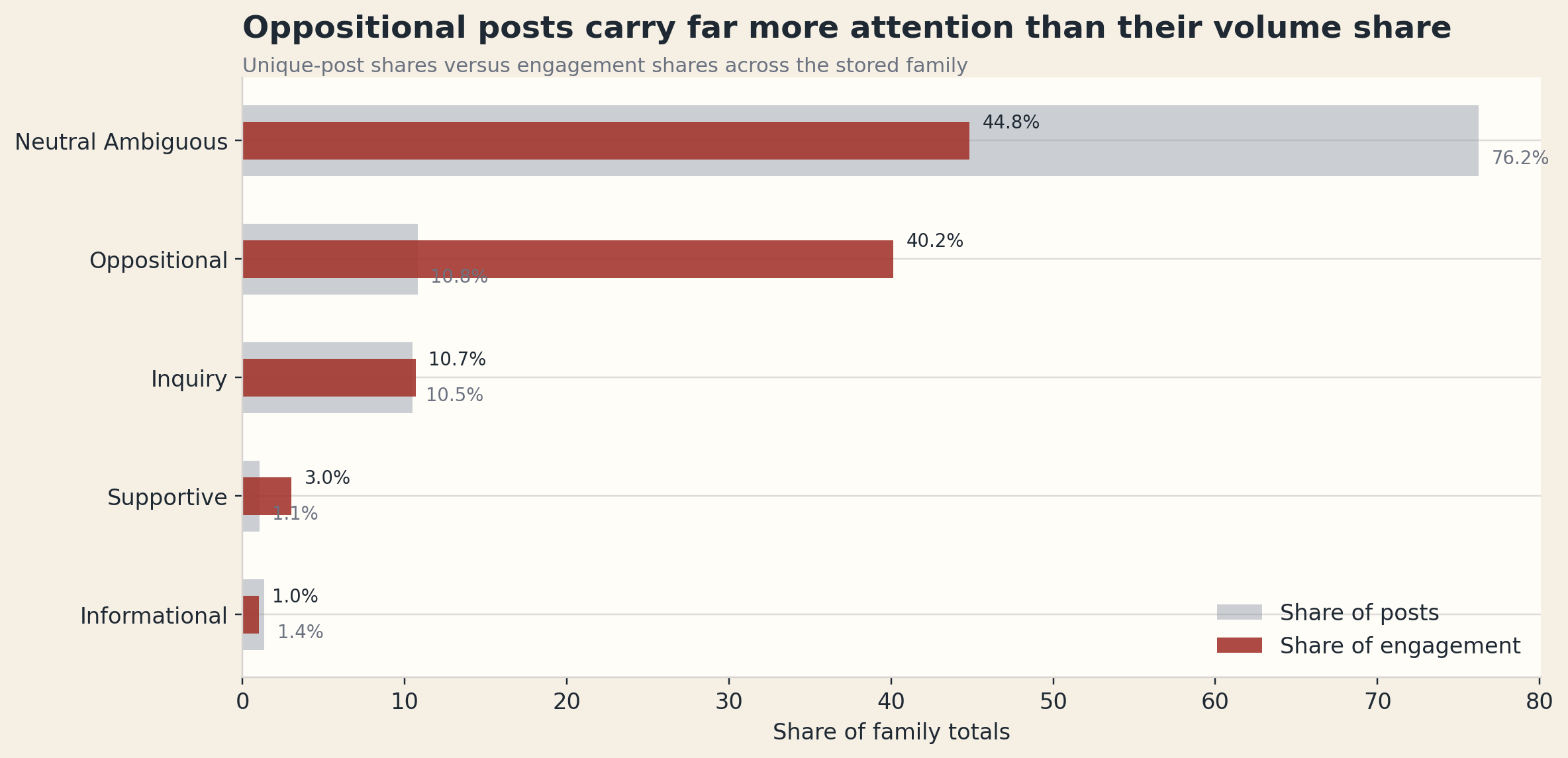
The clearest finding is where the attention goes once criticism enters the frame: criticism carries much more attention than its raw post count would suggest.
Attention Versus Count
In the unique-post family read:
38,744posts areneutral_ambiguous, which is76.25%of the corpus, but only44.82%of measured engagement5,495posts areoppositional, which is10.81%of the corpus, but40.15%of measured engagement5,331posts areinquiry, which is10.49%of the corpus and10.69%of engagement533posts aresupportive, which is1.05%of the corpus and3.03%of engagement
That is the cleanest reason I do not like flattening a topic into raw volume.
A smaller slice of the corpus can dominate the social meaning of the topic if it carries the heat.
For He Gets Us, oppositional posts do exactly that.
False Neutral Is A Real Problem Here
One of the improvements in the newer analysis stack is that it no longer lets “neutral†act like a lazy remainder bucket.
The current family read flags 12,457 posts as false-neutral candidates. These are rows that look neutral to basic sentiment methods but still carry loaded stance, rhetorical, or framing signals.
Campaign language often breaks simple sentiment tools, especially when the tone stays calm while the framing stays loaded.
A post can be calm in tone and still be clearly:
- theological critique
- provenance critique
- skeptical inquiry
- political critique
Without a stronger neutral audit, too much of this campaign would disappear into mush.
Narrative Tremors Matter More Than Generic Topics
The deeper narrative read is where the corpus gets much more useful.
Largest narrative surfaces in the current family:
Funding / Provenance:1,837posts, peak day2024-02-12Media / Platform Flashpoint:772posts, peak day2023-02-13Confusion / Inquiry:718posts, peak day2024-02-12Theology Critique:448posts, peak day2024-02-12
The smallest but hottest narrative is the one I keep coming back to:
Super Bowl Backlash: only57posts by count, but189,368total engagement
That is exactly why “attention versus count†needs to sit near the front of the analysis. A narrative does not need to be large to become decisive in the public read.
The Deeper Theological And Political Read
The strongest theological scorecard in the family is still Compassion / Identification, with 12,806 matching posts.
The larger theological surface still needs company.
The campaign is also repeatedly shadowed by:
Orthodoxy Conflict:3,039postsFunding / Control:2,778postsImmigration / Culture-War:2,214posts
Taken together, those surfaces show the campaign moving through several public frames at once:
- compassion language
- orthodoxy disputes
- funding questions
- culture-war association
That is why a single sentiment score does not describe this topic well enough.
Who Carries The Conversation
The current user-importance surface also helps because it separates repetition from impact.
A few examples make the point:
HeGetsUsis the highest-importance account in the family by sustained presenceTerriGreenUSAandIsThereAGod9matter because they are durable repeat participantsj_bambrick,andrewperezdc, andksorbsmatter because smaller post counts can still drive disproportionate attention
The cleanest example is Kevin Sorbo on 2025-02-10: one post, 118,040 engagement.
That is why public discourse work needs a carrier read. One account does not have to be prolific to become central.
What The Corpus Can Support Next

At this point, the corpus is large enough to support more than dashboard snapshots.
The He Gets Us internal corpus now carries:
57,951stored posts across the client-scoped family25,115token types273,769bigrams339,554trigrams29,607observed authors
And the modeling lane already exposes:
57,951sparse-design rows2,613features- about
1.05%density
That is a big shift in capability.
It means the work is no longer just:
- look at a dashboard
- hand-pick a few posts
- write a memo
That opens a few next-step lanes:
- reusable dictionary growth
- better phrase learning
- stronger supervised follow-ons later
- cleaner comparison across future client topics
The current recommendation in the modeling lane is still the right one: beat the problem with sparse GLM-style baselines before reaching for heavier stacks.
The point is not to avoid heavier models; it is to make them earn their place after the sparse baseline has done the obvious work.
What X Can And Cannot Tell You
This is the point I care about most.
X can tell you a lot about:
- narrative timing
- reaction intensity
- public language
- controversy structure
- elite and highly online carrier behavior
X cannot, by itself, tell you whether a huge campaign spend moved the general population the same way.
That is why I think the right relationship between this dataset and the survey work is complementary, not competitive.
The tracking work answers population questions.
The X work answers:
- what language broke through
- when it broke through
- what arguments attached to it
- and which slices of that argument carried the most public heat
That is enough to make the X layer genuinely valuable.
It is just not the same thing as saying the X layer is the whole truth.
The Final Read
The deeper read leaves me with one practical conclusion.
He Gets Us on X is best understood as a campaign that repeatedly buys moments of interruption and leaves public interpretation somewhat up in the air.
I do not read that as campaign failure. I read it as a public text layer shaped by salience, contestation, theology, provenance, and attention concentration.
For a researcher, that is the useful part of the topic.