
I would hand this version to someone who wanted the whole story in one sitting.
I did not choose He Gets Us because it was random, or because it was the noisiest thing I could throw at a new tool. I chose it because it was a campaign I already knew unusually well. For years McQueen Analytics had a weekly tracking study running on the campaign. Over time that work touched more than 150,000 surveys. The center of gravity in those years was quant analysis, not X. The weekly tracker was the main instrument. X, or Twitter at the time, gave me an adjacent read: useful, interesting, often revealing, but still secondary to the main measurement lane.
That history made it the right topic to revisit once I wanted to learn what the X API could still do in a serious research setting.
I was not meeting this topic cold
When you study a topic you already know well, you are much harder to fool.
I already knew this campaign had tent-pole moments. I already knew the Super Bowl windows mattered. I already knew there was a repeated public argument around compassion language, around who funded the campaign, around whether the ads softened or displaced harder politics, and around whether the theology was faithful or strategically vague. I had seen those patterns in survey work, in open-ended responses, in cross-tabs, in recurring weekly movement, and in the ordinary professional repetition that comes from staying with one campaign for a long time.
So when I came back through X, I was not asking the platform to tell me whether He Gets Us had ever mattered. I already knew it had mattered. I was asking a narrower and more useful question: what could a governed public-text layer still teach me, looking back, about a campaign I already understood from another angle?
A known topic creates a better learning problem than a topic you know nothing about. Without a prior read, the tool can impress you too easily. A new API, a new dashboard, a new corpus method, or a new model can feel smarter than it is simply because you do not have enough context to challenge it.
With He Gets Us, I did.
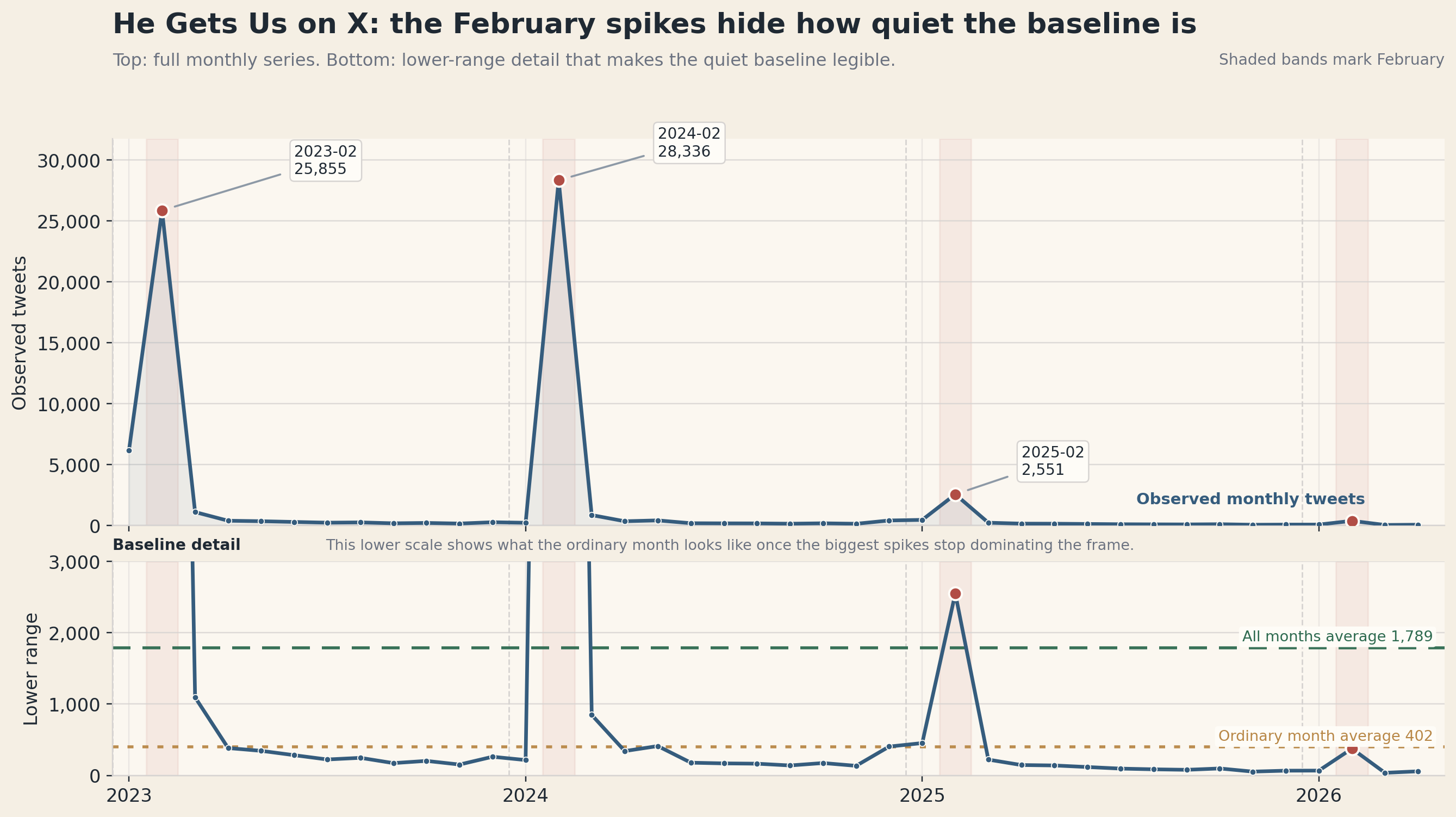
The monthly shape is a good example. If a pull on this topic did not come back overwhelmingly February-shaped, that would not feel like an exciting surprise. It would feel wrong. If the language layer did not keep surfacing terms around Jesus, the Super Bowl, feet-washing language, funding questions, and backlash, I would not assume the campaign had quietly changed character. I would assume I had asked the platform the wrong question or pulled the wrong lane.
In practice, prior knowledge becomes quality control.
Secondary research in a field I already knew
The next important boundary is that this was secondary research, not first-contact discovery.
The tracking study had already done the heavy population work. In that lane, you ask broader questions about awareness, favorability, movement, segmentation, message reaction, and whether something is changing in the public at scale. A weekly tracker earns its keep by not flinching. It keeps asking, week after week, even when the headlines change and the people running the campaign would rather the signal stay simple.
X sits in a narrower lane: public language from the people who post, reply, argue over, quote, or amplify the work. I have to use it with that boundary in plain view.
Once I accepted that boundary, the value of the X work became easier to describe. Its job was to sharpen what the tracker could not see as well:
how the public language moved in real time, which arguments attached most intensely to the campaign, which windows concentrated attention, and how a relatively small slice of posts could end up carrying a disproportionate share of the social meaning.
The project became useful once I stopped asking it to do the wrong job.
What the tool taught me on known ground
The tool-learning lesson is not abstract. It showed up immediately in the cost mistakes and the design corrections.
My first He Gets Us pull was too naive. I pulled too broadly, pulled too much username-level material, and burned more research money than I should have. The mistake was operational, not conceptual. Because I knew the topic, I could tell the difference between useful breadth and expensive redundancy much faster than I could have on an unfamiliar subject.
The mistake pushed the work toward counts first, better query discipline, clearer sibling lanes, and a more governed split between broad direct discourse, post-only historical recovery, and owned-link amplification. The method got better because the topic was familiar enough to expose where the method was wasteful.
The analytical side had the same problem. He Gets Us is the kind of campaign that punishes lazy neutral buckets. The surface can sound warm and low-temperature while still carrying sharp provenance critique, theological critique, skeptical inquiry, or political suspicion. If I had not known the campaign well already, I might have been too impressed by a mushy sentiment layer. Instead, I knew the neutral pile was hiding real content, because I knew the campaign had always produced more structured disagreement than a generic positive-negative split could capture.
Known terrain teaches you where the tool lies to you, where it gets expensive, where it needs a better query, and where the first-pass output is under-reading the subject.
What X added beside the weekly tracker
The biggest thing X added was texture.
The tracker told me that the campaign had movement, that tent-pole moments mattered, and that public reaction was not one-dimensional. X gave me more detail on what the argument sounded like when it broke into public language. The campaign's X life was overwhelmingly interruption-shaped rather than calm and continuous. The most important public disputes were not generic “people liked it†versus “people hated it,†but recurring clusters around theology, provenance, authenticity, media flashpoints, and political suspicion.
It also showed me something the public text layer is especially good at showing: the way attention concentrates around the hottest slice of the argument.
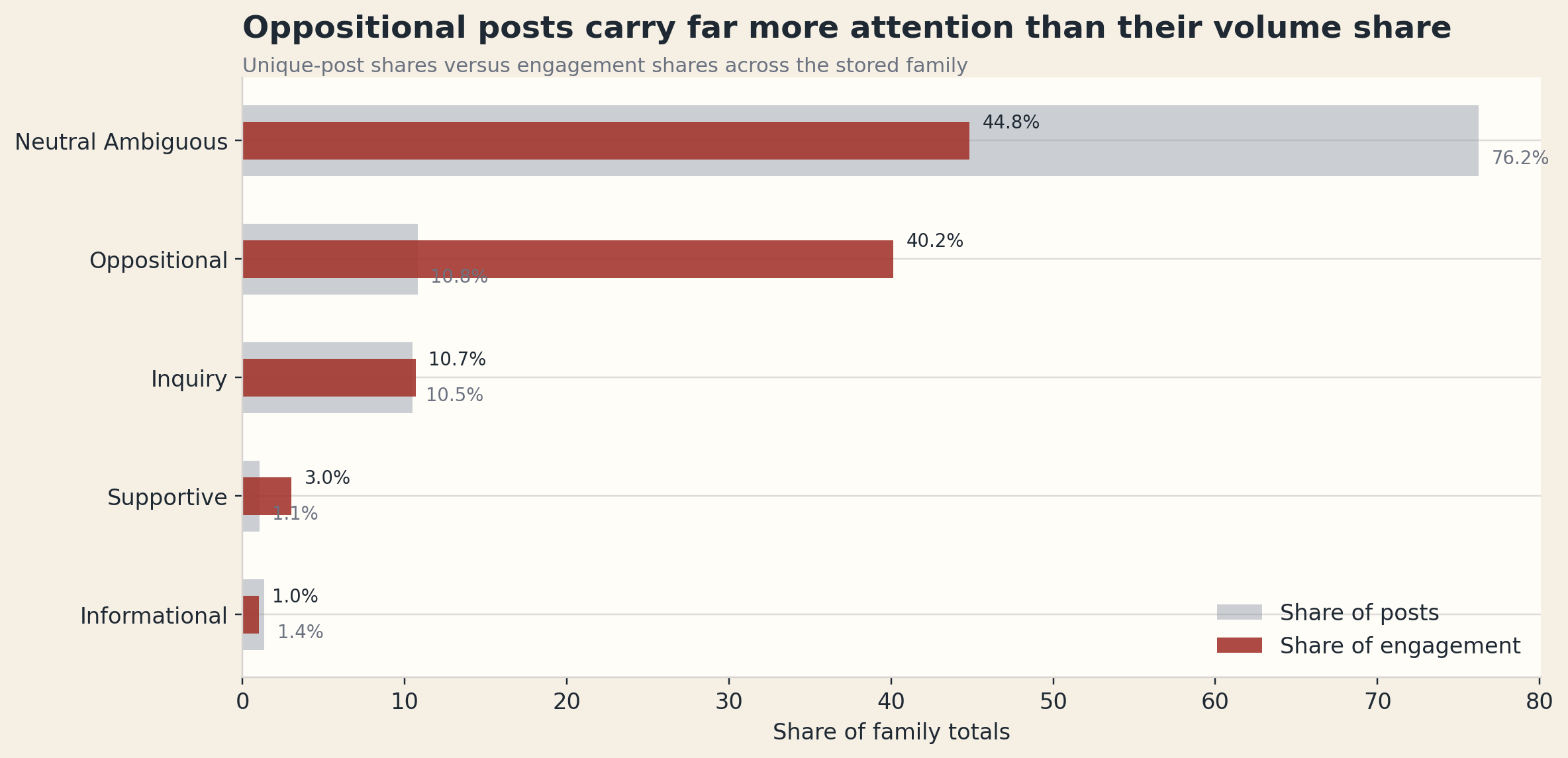
neutral_ambiguous by raw post share, but the oppositional slice carries a much larger share of engagement and therefore more interpretive weight.
The attention split became one of the most useful findings in the project. The corpus is mostly neutral_ambiguous by raw post share, but oppositional posts carry a much bigger share of engagement than their count alone would suggest. That changes how I describe the campaign's public layer. The campaign could create large moments of interruption and still leave interpretation somewhat unsettled. It could dominate a moment while the most consequential reaction came from the hottest slice by attention, not the biggest slice by raw count.
I need both pieces for different reasons: the tracker for population movement, X for public argument and attention concentration.
Looking back changed the question
If I had done this work during the core campaign years with the current project and current stack, I probably would have used it differently. I would have been more disciplined about separating direct discourse from amplification. I would have treated grouped windows and attention-versus-count as first-class outputs earlier. I would have pushed harder against neutral sooner. And I would have used the X layer more deliberately to inform open-end batteries and weekly tracker interpretation, as more than an anecdotal side monitor sitting off to the side in TweetDeck.
For me, the honest outcome is that the campaign teaches you something and your own method gets exposed at the same time.
Secondary research on known ground can still teach you something new, especially when the new thing is not the underlying topic but the instrument. In that sense, this project was as much about operator maturity as it was about He Gets Us. The campaign was the proving ground. The durable takeaway was about how to build a governed public-text lane that is cheap enough to use, disciplined enough to trust, and specific enough to complement serious quant work instead of pretending to replace it.
Bigger than one campaign read
By the end of this, I had a cleaner set of findings about He Gets Us and a better way to get there.
The outcome was a better method, a clearer workflow, and a more honest understanding of what public text can and cannot do well.
The workflow is more disciplined now. It starts with counts, keeps the query honest, separates direct discourse from amplification, and lets me move from stored evidence into public writing without reopening the API every time. That turns one expensive lesson into a reusable method.
And on the campaign itself, the final read is cleaner now than it would have been if I had stayed only with memory or only with the tracker. Looking back through X does not tell me whether the campaign persuaded America; I would use the tracker for that question. The X layer gives me a more careful sentence: He Gets Us repeatedly created public interruption, repeatedly drew structured argument, and often left interpretation open enough for the most intense reactions to carry extra weight.
I find that useful after the fact because it clarifies what kind of research instrument X really is.
Why I would recommend this path
If someone asked me how to learn a new public-text tool well, I would not tell them to start with the noisiest topic on earth or the most unfamiliar domain they can find. I would tell them to start with a topic they already know from another strong method.
Pick something where you already know the timing should spike. Pick something where you already know what kinds of words ought to show up. Pick something where you already know the difference between a plausible result and a broken pull. That way the tool has to prove itself against reality instead of merely sounding sophisticated.
He Gets Us gave me a topic with enough prior knowledge to make the X layer answerable.
For me, that was the outcome that made the whole project worth doing.